|
Wenshuai Zhao I am a postdoctoral researcher in the Department of Computer Science at Aalto University, Finland. I am supervised by Prof. Juho Kannala and Prof. Arno Solin. My PhD research, supervised by Prof. Joni Pajarinen, focused on reinforcement learning, imitation learning, and their applications in robotics and general decision-making. Currently, my research interests include robot perception, particularly 3D scene understanding and physics-based dynamics modeling.Email: wenshuai [dot] zhao [at] aalto [dot] fi |

|
Selected PublicationsI have done several projects on imitation learning, mutli-agent reinforcment learning, curriculum learning and model-based reinforcement learning. Representative papers are highlighted. Please check my Google Scholar for more details. |
Multi-agent Reinforcement Learning |
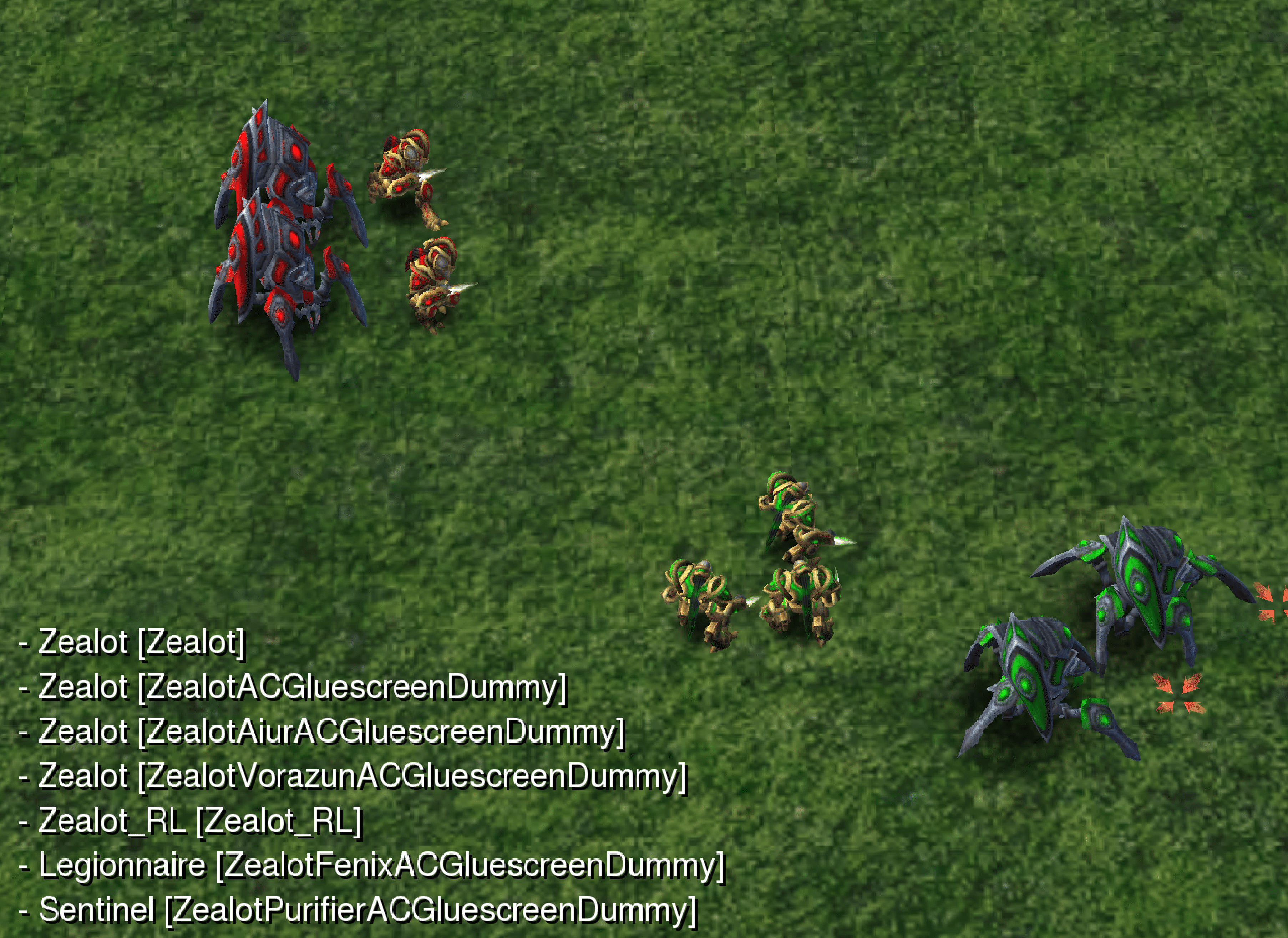
|
Learning Progress Driven Multi-Agent Curriculum
Wenshuai Zhao, Zhiyuan Li, Joni Pajarinen ICML, 2025 website / code / arXiv We show two flaws in existing reward based curriculum learning algorithms when generating number of agents as curriculum in MARL. Instead, we propose a learning progress metric as a new optimization objective which generates curriculum maximizing the learning progress of agents. |
|
AgentMixer: Multi-Agent Correlated Policy Factorization
Zhiyuan Li, Wenshuai Zhao, Lijun Wu, Joni Pajarinen AAAI, 2025 code / arXiv We propose multi-agent correlated policy factorization under CTDE, in order to overcome the asymmetric learning failure when naively distill individual policies from a joint policy. |
|
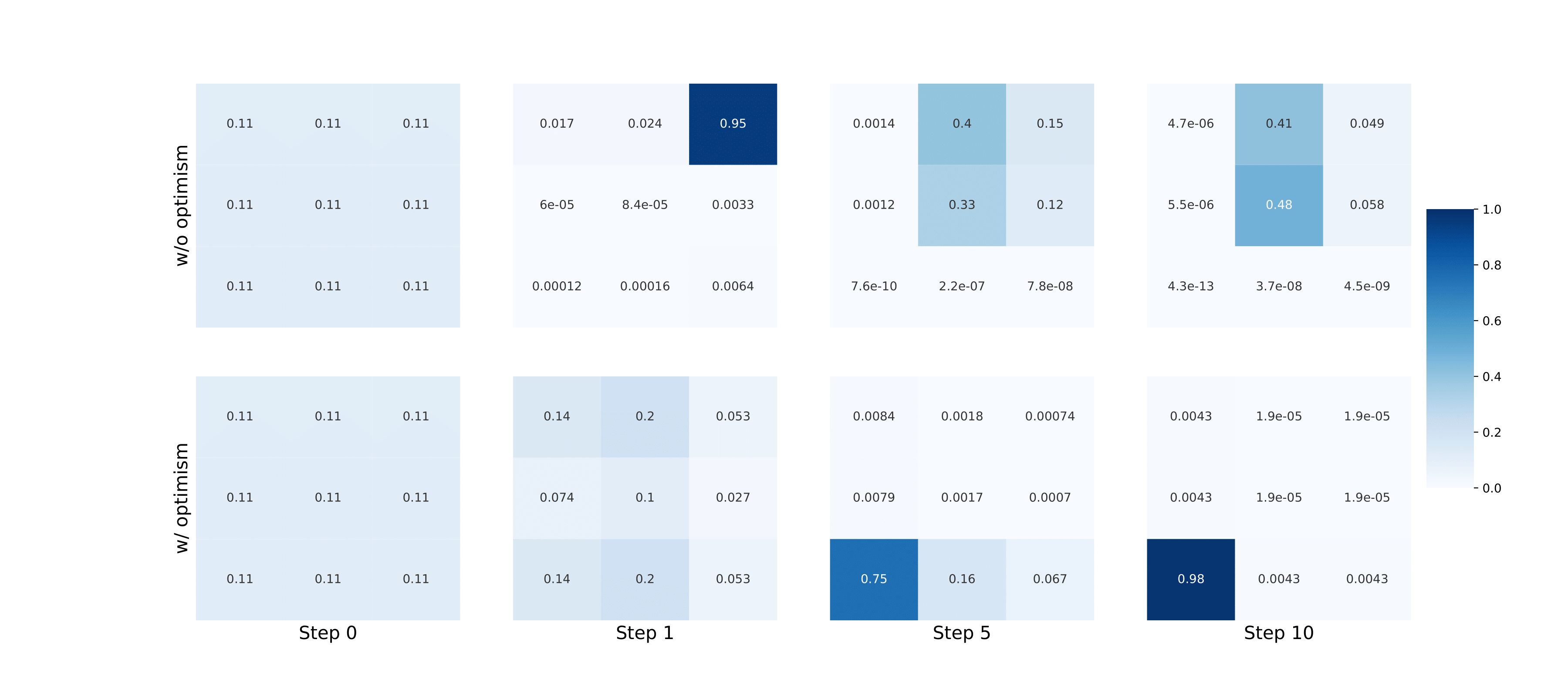
Optimistic Multi-Agent Policy Gradient
Wenshuai Zhao, Yi Zhao, Zhiyuan Li, Juho Kannala, Joni Pajarinen ICML, 2024 website / code / arXiv In order to overcome the relative overgeneralization problem in multi agent learning, we propose to enable optimism in multi-agent policy gradient methods by reshaping advantages. |
|
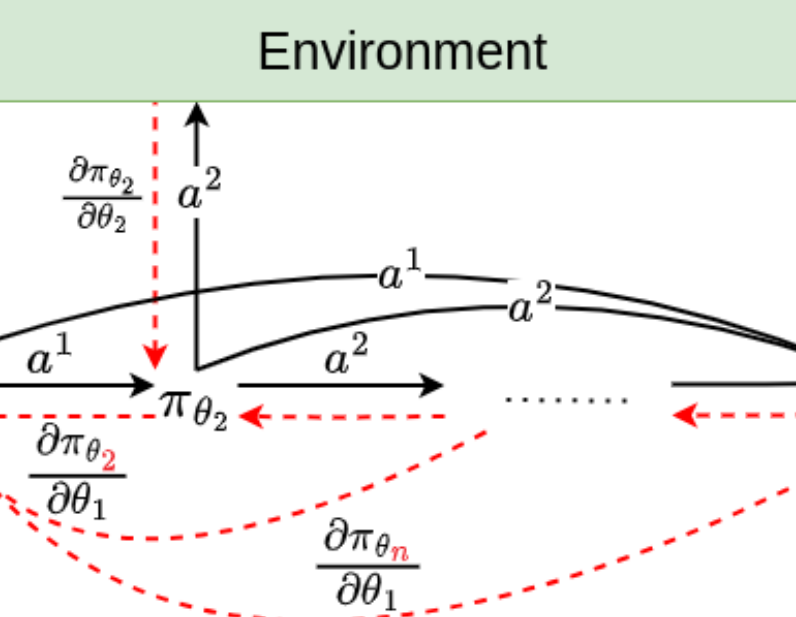
Backpropagation Through Agents
Zhiyuan Li, Wenshuai Zhao, Lijun Wu, Joni Pajarinen AAAI, 2024 code / arXiv We propose to backpropogate the gradients through action chains in auto-regressive based MARL methods. |
Robot Learning |

|
Bi-Level Motion Imitation for Humanoid Robots
Wenshuai Zhao, Yi Zhao, Joni Pajarinen, Michael Muehlebach CoRL, 2024 website / code / arXiv We propose a bi-level optimization framework to address the issue of physically infeasible motion data in humanoid imitation learning. The method alternates between optimizing the robot's policy and modifying the reference motions, while using a latent space regularization to preserve the original motion patterns. |

|
Exploiting Local Observations for Robust Robot Learning
Wenshuai Zhao*, Eetu-Aleksi Rantala*, Sahar Salimpour, Zhiyuan Li, Joni Pajarinen, Jorge Pena Queralta arXiv, 2025 code / arXiv We show that in many multi agent systems where agents are weakly coupled, partial observation can still enable near-optimal decision making. Moreover, in a mobile robot manipulator, we show partial observation of agents can improve robustness to agent failure. |
Model-based Reinforcement Learning |

|
Simplified Temporal Consistency Reinforcement Learning
Yi Zhao, Wenshuai Zhao, Rinu Boney, Juho Kannala, Joni Pajarinen ICML, 2023 code / arXiv We propose a simple but effective model-based reinforcement learning algorithm relying only on a latent dynamics model trained by latent temporal consistency. |
|
|
|
Design and source code from Jon Barron's website |